Un outil de
gestion des contenus
Un outil de gestion des contenus patrimoniaux
Le choix a été fait de ne pas développer un système entier mais d’utiliser des logiciels existants et ouverts. Ces logiciels répondent chacun de leur côté à une partie des besoins des différents projets de recherche, les différentes fonctionnalités sont reliées dans un système centralisé, ici Omeka S. Celui-ci est une application inspirée de Content Management Systems (CMS) et il est développée en code ouvert par le Centre Roy Rosenzweig de l'Université George Mason (Etats-Unis). Omeka-S centralise les données géoréférencées y compris les métadonnées, les données sont également diffusées en flux WMS grâce à un serveur cartographique comme GeoServer. Une seule interface administrateur permet la publication de sources, enrichies sémantiquement par l’utilisateur, et rend possible la gestion de plusieurs sites. Cette fonctionnalité convenait parfaitement au type de plateforme envisagé dans le projet. L’architecture de la plateforme est présentée en figure 1.
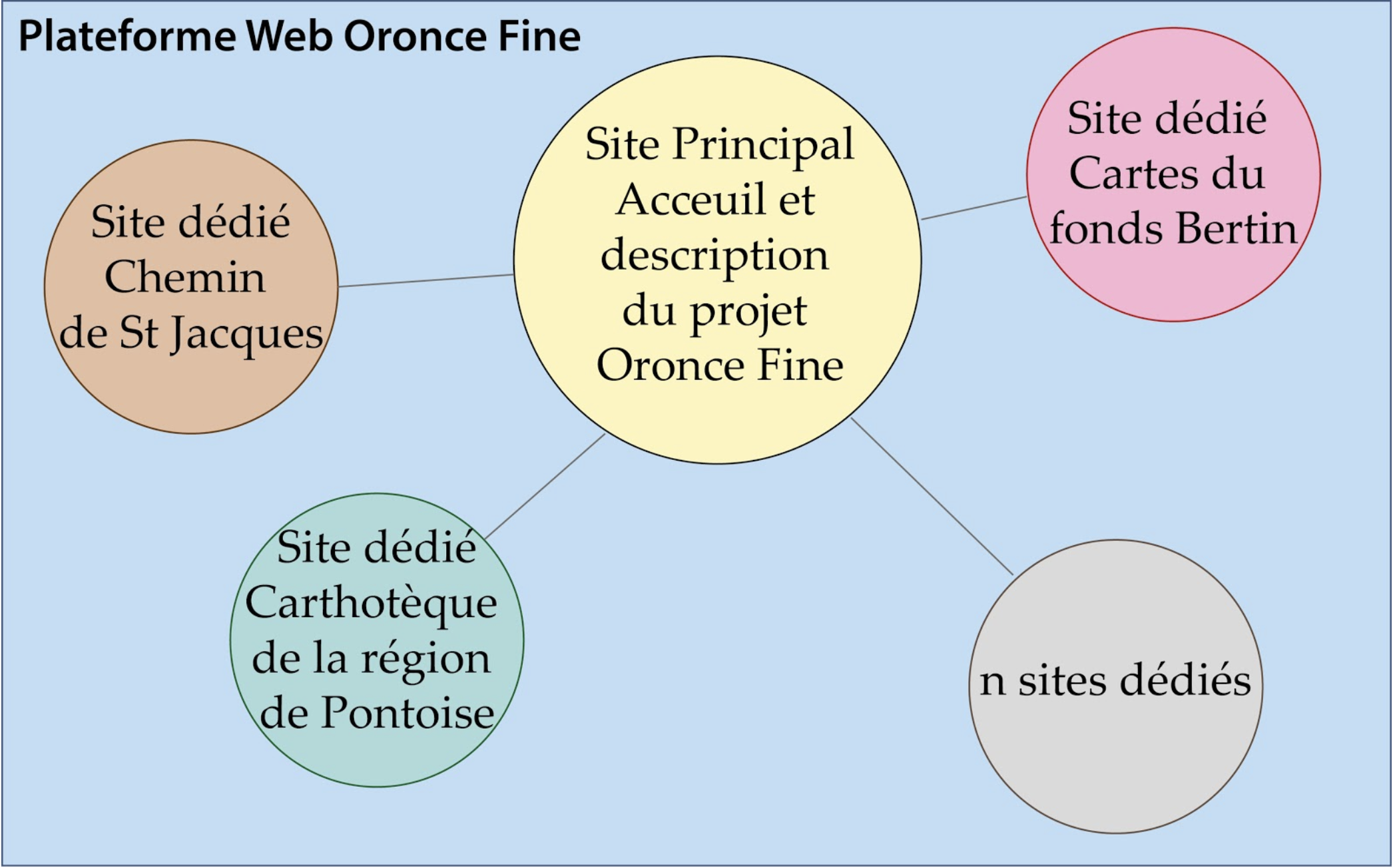 FIGURE 1. Architecture multi-site de la plateforme Oronce Fine
FIGURE 1. Architecture multi-site de la plateforme Oronce Fine
3. Géoréférencement et intégration
Les sources cartographiques suivent un processus prédéfini de géoréférencement et d’intégration à Omeka S. Ce processus est présenté en figure 2. Ces sources regroupent des documents se présentant sous diverses formes : plans, cartes, images, diapositives, articles, cartes postales, témoignages, etc. Le processus de géoréférencement et d’intégration se déroule en trois phases. Durant la première phase les documents sont numérisés et mis en forme en local par les équipes de recherche, puis envoyés sur le serveur d’hébergement en ligne. Sur le serveur, lors de la seconde phase, les données sont normalisées et intégrées à Omeka S ; un identifiant par document, de type ARK dans les meilleurs des cas, au sein du système est choisi. La troisième et dernière phase consiste à utiliser Omeka S pour enrichir par des annotations les données et les diffuser sur le web.
Dans le détail, localement les documents sont, dans un premier temps, numérisés. Ces documents sont ensuite collectés et rassemblés dans un même fichier. L’ensemble des données stockées dans le fichier sont alors décrites par leurs métadonnées. Chaque document est ainsi intégré sous forme d’une ligne à un tableur préformaté. Ce tableur contient des champs correspondant à la description normée des documents et de leur contenu. Les données pouvant être géoréférencées sont traitées sous le logiciel QGis. Les images sont géoréférencées généralement sur des fonds types Open Street map en WGS84. Une fois géoréférencées l’emprise des contenus est extraite par vectorisation. Le vecteur ainsi obtenu permet de découper les images géoréférencées pour ne garder que le contenu spatialisé. Cette emprise est aussi stockée en WKT pour servir plus tard le processus d’annotation spatiale sous omeka S.
Toutes les données envoyées sur le serveur font l’œuvre d’un traitement particulier. À ce stade l’ensemble du processus est automatisé par un script. Les numérisations des documents sources sont réparties dans des dossiers de stockages préformatés. Les données images sont stockées à la fois sous forme brute en vues d’être disponible au téléchargement et sous forme retraitées afin d'être intégrées aux sites diffusés par omeka S. Les images géoréférencées sont de leurs côtés normalisées et tuilées par un script Gdal pour ensuite être intégrées à un Géoserver par l’api REST. Le Géoserver a pour rôle ici de diffuser ces images sous forme de WMS. Enfin le tableur contenant les métadonnées subit lui aussi des modifications car les champs préformatés sont mappés sur des ontologies choisies : Dublin Core, Bibliographic Ontology et INSPIRE pour les cas d’études précédemment cités. Le tableur est ensuite transformé en CSV et stocké sur le serveur.
À l’issue de la phase de retraitement sur le serveur les données sources se présentes sous formes d’images brutes ou retraitées, de WMS émis par le geoserver et d’un CSV contenant les métadonnées. Tous ces éléments sont intégrés à Omeka S via l’api Rest. Les métadonnées du CSV deviennent des items décrits par des métadonnées. Les images retraitées sont associées à ces items sous formes de media et les images brutes sont présentent sous formes de liens de téléchargement. Sous Omeka S grâce à deux modules développé dans le cadre du projet Oronce Fine il est désormais possible d’annoter à la fois le contenu des images (media) lui-même et d’annoter spatialement les données. C’est à cette étape généralement que l’on récupère les emprises vectorisées sous Qgis pour les intégrer sous forme d’annotation. Omeka S va enfin sous forme de Sites web diffuser les items, les media, les annotations et les WMS dans les sites propres à chaque cas d’étude. Les métadonnées sont aussi diffusée selon le protocole OAI-PMH.